The import of PDF files, i.e. the transfer of content from PDF files into an article (text format) is technically a challenge, and due to the many different starting situations not every import succeeds in the desired way.
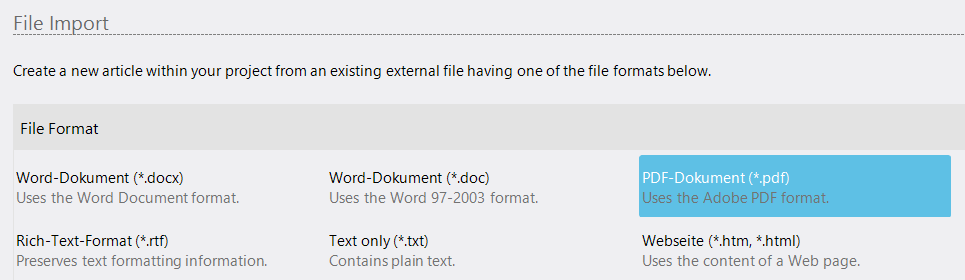
In the following, the special features of importing PDF files will be discussed in more detail.
PDF is a format for describing document pages. Its original purpose was to display documents on different operating system platforms while retaining the layout and formatting as much as possible. It was never intended to completely return content from PDF files to text form.
A PDF file contains detailed information about the appearance of characters, but not necessarily about their meaning. This means that it is precisely defined how a character has to look like and where it is located in the document. However, there is no information about the standardization of the character. For this reason, the import of text from PDF files is in many cases only possible with restrictions.
Apart from the lack of information on standardization, there is a lack of any information on order and text flow and on whether a text component represents a heading or is located in a table. Although recent improvements in the PDF format specification allow it, such information is rarely included in PDF documents. Fortunately, the majority of PDF documents contain some form of character mapping that allows a PDF reader to convert text to a Unicode string.
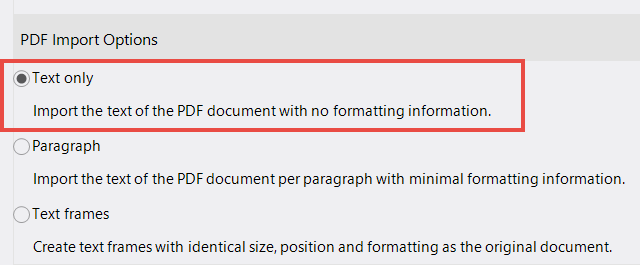
If you select "Text only" under "PDF Import Options" lexiCan extracts and transfers all text components it finds, adds missing spaces and line breaks and sorts text blocks so that they appear in their logical order. The resulting text then consists of individual text lines with a line break at the end of each line.
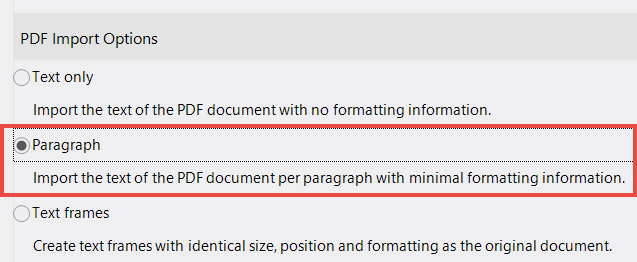
When importing with the help of "paragraph recognition" lexiCan can combine these single text lines to larger text blocks, which makes editing the text more comfortable.
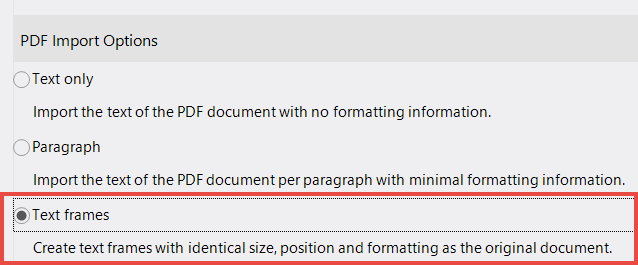
The third option allows you to display text in frames. This allows the original layout of the PDF document to be retained and - not unimportant - image components to be taken into account.
Importing Articles from other Projects